
Introduction to machine learning
WHAT IS MACHINE LEARNING?
This article covers the introduction to machine learning and the directly related concepts.
Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed. It is a subset of artificial intelligence (AI) and computer science that focuses on the use of data and algorithms to imitate the way humans learn, and in doing so it gradually improving its accuracy. By using statistical learning (link resides outside Axisto) and optimisation methods, computers can analyse datasets and identify patterns in the data. Machine learning techniques leverage data mining to identify historic trends to inform future models.
According to the University of California, Berkeley, the typical supervised machine learning algorithm consists of three main components:
- A decision process: A recipe of calculations or other steps that takes in the data and returns a guess at the kind of pattern in the data that the algorithm is looking to find.
- An error function: A method of measuring how good the guess was by comparing it to known examples (when they are available). Did the decision process get it right? If not, how do you quantify how bad the miss was?
- An updating or optimisation process: The algorithm looks at the miss and then updates how the decision process comes to the final decision so that the miss will not be as great the next time.
Machine learning is a key component in the growing field of data science. Using statistical methods, algorithms are trained to make classifications or predictions and uncover key insights from data.
HOW DOES A MACHINE LEARNING ALGORITHM LEARN?
The technology company Nvidia (link resides outside Axisto) distinguishes four learning models that are defined by the level of human intervention:
- Supervised learning: If you are learning a task under supervision, someone is with you, prompting you and judging whether you’re getting the right answer. Supervised learning is similar in that it uses a full set of labelled* data to train an algorithm.
- Unsupervised learning: In unsupervised learning, a deep learning model is handed a dataset without explicit instructions on what to do with it. The training dataset is a collection of examples without a specific desired outcome or correct answer. The neural network then attempts to automatically find structure in the data by extracting useful features and analysing its structure. It learns by looking for patterns.
- Semi-supervised learning: Semi-supervised learning is, for the most part, just what it sounds like: a training dataset with both labelled and unlabelled data. This method is particularly useful in situations where extracting relevant features from the data is difficult or where labelling examples is a time-intensive task for experts.
- Reinforcement learning: In this kind of machine learning, AI agents are trying to find the optimal way to accomplish a particular goal or improve the performance of a specific task. If the agent takes action that moves the outcome towards the goal, it receives a reward. To make its choices, the agent relies both on learnings from past feedback and on exploration of new tactics that may present a larger payoff. The overall aim is to predict the best next step that will earn the biggest final reward. Just as the best next move in a chess game may not help you eventually win the game, the best next move the agent can make may not result in the best final result. Instead, the agent considers the long-term strategy to maximise the cumulative reward. It is an iterative process: the more rounds of feedback, the better the agent’s strategy becomes. This technique is especially useful for training robots to make a series of decisions for tasks such as steering an autonomous vehicle or managing inventory in a warehouse.
* Fully labelled means that each example in the training dataset is tagged with the answer the algorithm should produce on its own. So a labelled dataset of flower images would tell the model which photos were of roses, daisies and daffodils. When shown a new image, the model compares it to the training examples to predict the correct label.
In all four learning models, the algorithm learns from datasets based on human rules or knowledge.
In the domain of artificial intelligence, you will come across the terms machine learning (ML), deep learning (DL) and neural networks (artificial neural networks – ANN). Artificial intelligence and machine learning are often used interchangeably, as are machine learning and deep learning. But, in fact, these terms are progressive subsets within the larger AI domain, as illustrated in Figure 1.
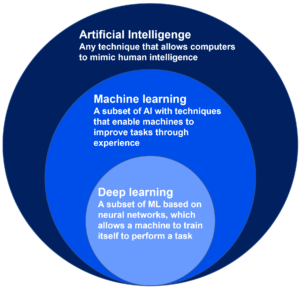
Therefore, when discussing machine learning, we must also consider deep learning and artificial neural networks.
THE DIFFERENCE BETWEEN MACHINE LEARNING AND DEEP LEARNING IS THE WAY AN ALGORITHM LEARNS
Unlike machine learning, deep learning does not require human intervention to process data. Deep learning automates much of the feature extraction piece of the process, eliminating some of the manual human intervention required, which means it can be used for larger data sets.
“Non-deep” machine learning is more dependent on human intervention for the learning process to happen because human experts must first determine the set of features so that the algorithm can understand the differences between data inputs, and this usually requires more structured data for the learning process.
“Deep” machine learning can leverage labelled datasets, also known as supervised learning, to inform its algorithm. However, it does not necessarily require a labelled dataset. It can ingest unstructured data in its raw form (e.g., text and images), and it can automatically determine the set of features that distinguishes between different categories of data. Figure 2 illustrates the difference between machine learning and deep learning.
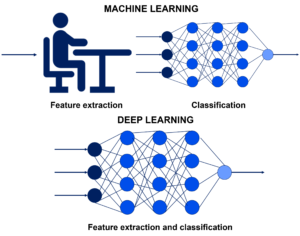
Deep learning uses multiple layers to progressively extract higher-level features from the raw input. For example, in image processing, lower layers may identify edges, while higher layers may identify the concepts relevant to a human, such as digits or letters or faces.
In deep learning, each level learns to transform its input data into a slightly more abstract and composite representation. In an image-recognition application, the raw input may be a matrix of pixels. The first representational layer may abstract the pixels and encode edges; the second layer may compose and encode arrangements of edges; the third layer may encode a nose and eyes; and the fourth layer may recognise that the image contains a face. Importantly, a deep learning process can learn which features to optimally place in which level on its own. This does not fully eliminate the need for manual-tuning – for example, varying numbers of layers and layer sizes can provide different degrees of abstraction. The word “deep” in “deep learning” refers to the number of layers through which the data is transformed.
NEURAL NETWORKS
An artificial neural network (ANN) is a computer system designed to work by classifying information in the same way a human brain does, while still retaining the innate advantages they hold over us, such as speed, accuracy and lack of bias. For example, it can be taught to recognise images and classify these according to elements they contain. Essentially, it works on a system of probability – based on data fed to it, it can make statements, decisions or predictions with a degree of certainty. The addition of a feedback loop enables “learning” – by sensing or being told whether its decisions are right or wrong, it modifies the approach it takes in the future.
Artificial neural networks consist of a multilevel learning of detail or representations of data. Through these different layers, information passes from low-level parameters to higher-level parameters. These different levels correspond to various levels of data abstraction, leading to learning and recognition. An ANN is based on a collection of connected units called artificial neurons (analogous to biological neurons in a biological brain). Each connection (synapse) between neurons can transmit a signal from one neuron to another neuron. The receiving (postsynaptic) neuron can process the signal(s) and then signal to neurons connected to it downstream. Neurons may have state, generally represented by real numbers, typically between 0 and 1. Neurons and synapses may also have a weight that varies as learning proceeds, which can increase or decrease the strength of the signal that it sends downstream. Typically, neurons are organised in layers, as illustrated in Figure 3. Different layers can perform various kinds of transformations on their inputs. Signals travel from the first (input), to the last (output) layer, possibly after traversing the layers multiple times.
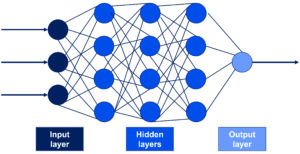
USES OF MACHINE LEARNING
There are many applications for machine learning; it is one of the three key elements of Intelligent Automation and a autonomous operating model within Industry 4.0. The computer programs can read text and work out whether the writer was making a complaint or offering congratulations. They can listen to a piece of music, decide whether it is likely to make someone happy or sad, and find other pieces of music to match the mood. In some cases, they can even compose their own music that either expresses the same themes or is likely to be appreciated by the admirers of the original piece.
Neural networks have been used on a variety of tasks, including computer vision, speech recognition, machine translation, social network filtering, playing board and video games, and medical diagnosis. As of 2017, neural networks typically have a few thousand to a few million units and millions of connections. Although this number is several orders of magnitude less than the number of neurons in a human brain, these networks can perform many tasks at a level beyond that of humans (e.g., recognising faces, playing “Go”).

Articles
